ウェブ運用の工数削減に役立つ
AI活用術39選
ウェブ運用の膨大なタスクを「CMS×AI」で削減する39個のユースケースをご紹介します。単なるテキスト生成を超え、AIがCMS操作そのものを支援する次世代の運用フローをご覧ください。
39個のAI活用術を見るAI時代のウェブサイト運用ノウハウ
最終更新日:2026.6.10



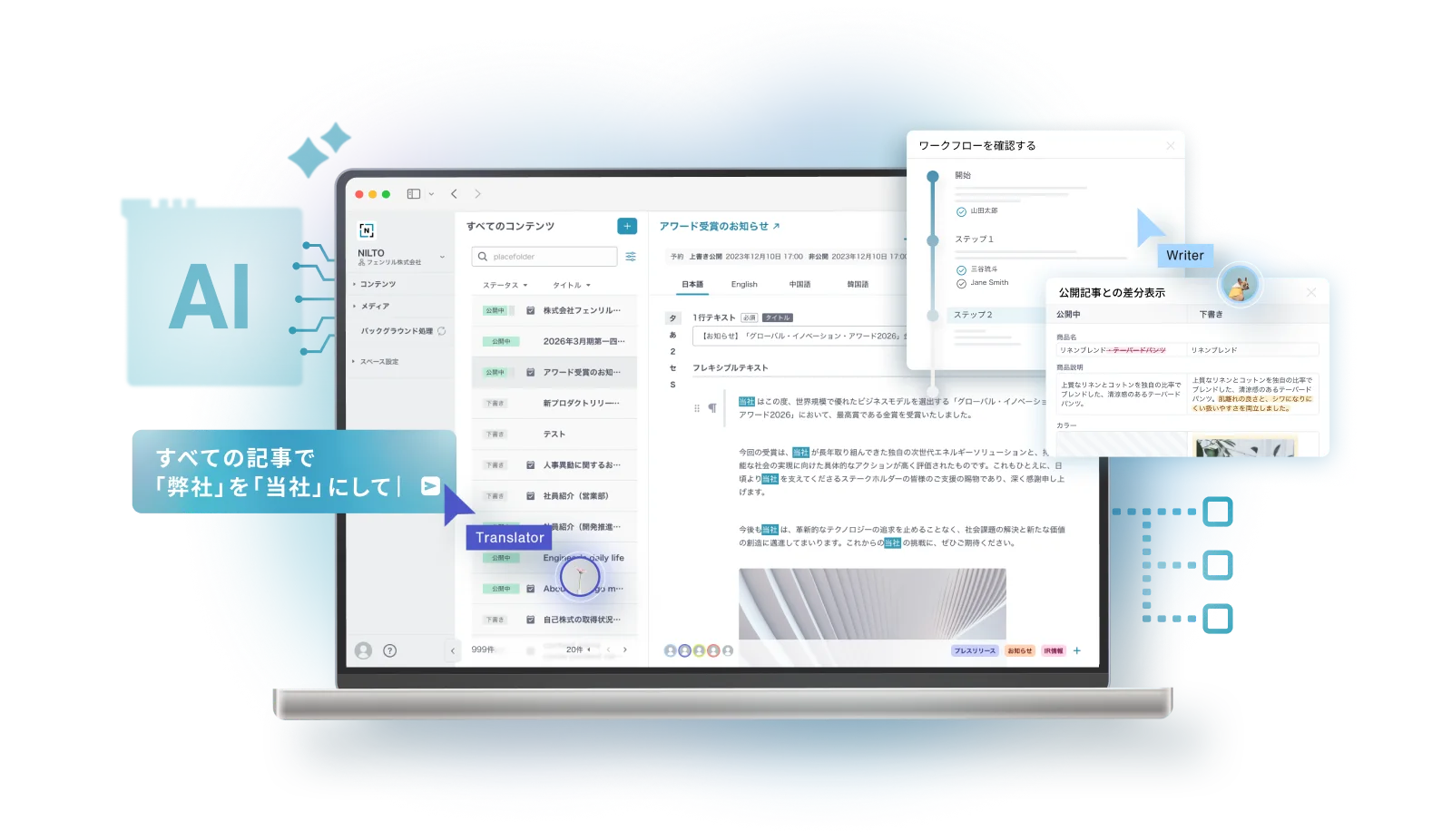
ウェブ運用の工数削減に役立つ
AI活用術39選
ウェブ運用の膨大なタスクを「CMS×AI」で削減する39個のユースケースをご紹介します。単なるテキスト生成を超え、AIがCMS操作そのものを支援する次世代の運用フローをご覧ください。
39個のAI活用術を見るコンテンツモデリング(Content Modeling)とは、Webサイトやアプリケーションで扱う情報を、特定の画面レイアウトやデザインから完全に切り離し、意味を持った「データの塊」として定義し、それらの構造と関係性を設計するプロセスのことです。
従来型CMSが「特定のページを表示するためのツール」であるのに対し、ヘッドレスCMSは「APIを介してマルチチャネルに構造化データを配信するデータベース」としての役割を持ちます。そのためコンテンツモデリングは、オブジェクト指向設計やRDBのスキーマ設計に近い性質を持ち、ヘッドレスCMS導入プロジェクトの成否を最も大きく左右する工程となります。
「ページ」を作る作業ではなく、「データの意味」を定義する作業──この発想の転換こそが、ヘッドレスCMSをうまく使いこなす最初の関門です。
現代のWebコンテンツは、PC・スマホのWebサイトだけでなく、ネイティブアプリ・IoTデバイス・デジタルサイネージ・社内システム連携など、多様なチャネルに配信されます。1つのコンテンツがどこで・どのように表示されるかを予測できない環境において、特定の「ページ」や「サイドバー」に依存したデータ構造を作ってしまうと、他チャネルへの転用が不可能になります。
コンテンツモデリングを正しく行い、データをピュアな「意味情報」として抽象化しておくことで、フロントエンド技術やデバイスが変わってもバックエンドのデータ構造を変更せず、最小コストで新しいチャネルへ展開できるようになります。
従来型CMSからの移行ニーズが高まる背景には、データ構造上の限界があります。社内へ移行提案する際は、まずこれらを正しく言語化しておく必要があります。
wp_postmetaの構造問題: ACFやCPT UI等のプラグインで追加したカスタムフィールドの多くは、wp_postmetaテーブルにEAV(Entity-Attribute-Value)パターンで縦持ち保存されます。フィールド数が増えると複雑なJOINが必要となり、インデックスが効かなくなりパフォーマンスが劣化する根本原因となります。WordPress自体をヘッドレス化して段階的に脱却するアプローチについては、以下の記事も参考にしてください。

2026-03-31T01:17:26Z
両者のデータ構造の違いを、コンテンツモデリングの観点で整理すると以下のようになります。
比較項目 | 従来型CMS(WordPress等) | ヘッドレスCMS |
|---|---|---|
設計の起点 | ページ・画面レイアウト | コンテンツ(意味)そのもの |
データの基本単位 | 投稿(Post) + カスタムフィールド | コンテンツモデル |
データの持ち方 | EAV的な縦持ち( | スキーマ定義に基づく構造化データ |
再利用性 | テーマ・サイトに依存 | API経由でマルチチャネルに配信 |
フロントエンド | テーマファイル(PHP)と密結合 | 完全分離(Next.js / Nuxt 等) |
フロントエンドでの型定義 | 弱い(取得時バリデーション必須) | 容易(APIスキーマからTS型の自動生成) |
多言語対応 | プラグイン依存・後付け改修が困難 | フィールド単位のロケール機能が標準 |
スキーマ変更時の影響 | テーマ全体に波及 | フロントエンドとAPIの契約で局所化 |
従来型CMSが「表示」を起点に設計されているのに対し、ヘッドレスCMSは「データ」を起点に設計されています。コンテンツモデリングは、この起点の違いを埋めるための設計工程と捉えると、その重要性がよく理解できます。
ヘッドレスCMSのメリットを最大限引き出すための具体的なモデリング手順を、4ステップに分けて解説します。
Webサイトを構成するすべての情報要素を、ワイヤーフレームや既存サイトの「見た目」から意図的に思考を切り離して洗い出します。対象ドメインに存在する「エンティティ(実体)」をリストアップする作業です。
「これは記事の一部か?それとも独立したエンティティか?」を問い続けるのがポイントです。
洗い出した要素から、再利用される共通要素や独立して管理すべき概念を抽出し、ヘッドレスCMS上の「モデル」として分割・定義します。データベース設計の「正規化」に近い作業です。
例えば「記事」に毎回「執筆者の名前・部署・顔写真・プロフィール文」を直接入力する設計にしてしまうと、その執筆者が異動したりアイコン画像を変えたりするたびに、過去に書いた数十〜数百本の記事をすべて手作業で修正する必要が出ます。
ここで「著者(Author)」を独立したモデルとして抽出して管理すれば、著者情報は1箇所更新するだけで、すべての関連記事に自動的に反映されます。これが「正規化」の威力です。
各モデルに持たせる属性(フィールド)を決め、最適な「データ型」を割り当てます。ヘッドレスCMSではフロントエンドがAPI(JSON形式)を介してデータを処理するため、型の選択がフロントエンドコードの堅牢性(TypeScriptの型定義など)に直結します。主要な型は以下のとおり。
独立させたモデル同士の「関係性(リレーション)」を、参照(Reference)フィールドで設計します。データベースのキー結合と同様、関係パターンには以下の3種類があります。
参照フィールドを設定することで、APIで記事データを取得した際に、紐づく著者やカテゴリのオブジェクトがネストされたJSONとして同時に返却され、フロントエンド側の非同期リクエスト回数を削減(ラウンドトリップの最適化)できます。
実際の開発現場で頻出する3つのユースケースについて、モデル構成を見ていきます。
「記事」「著者」「カテゴリ」の3モデルを連携させる、最も標準的な構成です。
モデル | 主要フィールド | リレーション |
|---|---|---|
|
|
|
|
| なし(他モデルから参照される) |
|
| なし(他モデルから参照される) |
ポイントは、published_atを持つことで未来日時の予約投稿を制御できる点、slugを重複不可にしてURLパスとして安定運用できる点、そして著者・カテゴリを独立モデル化することで一元管理を実現している点です。3モデルへ正規化することで、記事側からは参照フィールドを通じてシームレスにデータを利用できる、保守性の高い設計が実現します。
「製品」と「導入事例」をクロスリファレンス(相互参照)させる構成です。
product(製品情報): product_name / summary / features(リッチテキスト) / price / download_file(PDF)case_study(導入事例): company_name / logo / title / content / related_products(複数選択でproductを参照)この設計により、「製品詳細ページに導入事例を表示」しつつ「導入事例ページから製品にリンクを張る」という双方向の動的リンクが、データ重複なしで実現できます。
ヘッドレスCMS導入時にエンジニアが頭を悩ませがちなのが、「LPやトップページのように、パーツの並び順や構成がページごとに異なるレイアウト性の高い画面をどうモデリングするか」という問題です。これを解決するのが「コンポーネントベース(ブロックベース)設計」です。
多くのモダンヘッドレスCMSには、1つのモデル内に複数の異なる構造のブロックを配列で持てる機能(「ブロック」「スライス」「動的コンポーネント」などと呼ばれる)が備わっています。例えばpage_builderモデルがblocksフィールドを持ち、その配列に以下のようなコンポーネントを編集者が自由に並べる設計が可能です。
headline / subtext / bg_image / cta_urlitems(各要素はicon / title / description)quote / sourceフロントエンド側(例:Next.js)では、APIから返ってきたblocks配列をmapでループ処理し、各オブジェクトのtypeに応じて対応するReactコンポーネント(<HeroSection />や<FeatureGrid />)を動的にレンダリングするロジックを実装します。これにより、デザインの統一を保ったまま、編集者がノーコードに近い感覚で自由レイアウトのページを量産できる環境が整います。
初期設計で誤った構造を作ると、開発後半やリリース後に致命的な問題を引き起こします。回避すべき代表的なアンチパターンを7つ紹介します。
フィールド名やモデル名に、特定の画面レイアウトを前提とした名前を付けるパターンです。
top_page_right_red_button_text(トップページ右側の赤ボタンのテキスト)hero_cta_label(ヒーローエリアのコンバージョンボタンのラベル)デザインリニューアルでボタンの位置が左に変わったり、色が青になったり、あるいはアプリ向けにデータを出力することになった瞬間、データ名と実態が乖離してコードの可読性が著しく低下します。フィールド名はデザインではなく、「データが表す意味(セマンティクス)」に基づいて命名しましょう。
正規化を極限まで進め、あらゆる要素を別モデルに切り出してリレーションで繋いでしまうパターンです。記事内の目次や注意書きまで独立モデル化すると、以下のような問題が発生します。
モデルの分離は、「本当に他のエンティティから単体で再利用されるか」を基準にし、一過性のデータはモデル内のローカルなオブジェクト(またはコンポーネント機能)に留めましょう。
WordPressのクラシックエディタの感覚で、巨大なリッチテキストフィールドに文章・画像・表・インラインスタイル・カスタムHTMLをすべてベタ書きしてしまうパターンです。
これではヘッドレスCMSを導入した意味が完全に消失します。データの中身が「プレーンな情報」ではなく「HTMLタグが混ざった表示データ」になってしまうため、フロントエンド側で「画像だけを抽出してカルーセル表示にする」「文章の文字数をカウントして要約を作る」「ネイティブアプリでコンポーネントとしてパースする」といった処理が一切できなくなります。装飾やレイアウトを施したい場合は、ケース3で紹介したコンポーネントベース設計(ブロックの配列化)を正しく導入しましょう。
モデル同士が互いを生の参照フィールドで直接参照し合うパターンです。例えば「店舗」モデルが「所属スタッフ」モデルを参照し、同時に「スタッフ」モデルも「所属店舗」モデルを直接参照するようなケース。
多くのヘッドレスCMSはAPI側で参照の深さ(Depth)に上限を設けているため、サーバーダウンに至るケースは稀ですが、レスポンスデータが意図せず肥大化したり、ネスト制限に引っかかってフロントエンド側でデータが欠落する原因となります。エラーで止まらず黙ってデータが欠ける分、原因特定にも時間がかかる厄介な不具合です。
参照は原則として「親→子の単方向」にするか、どちらか一方はIDだけを保持してフロントエンド側で結合(クエリ側で解決)するなどの配慮が必要です。
サービスが成長するにつれ、後から「このモデルに新しいフィールドを追加したい」「古いフィールドを削除したい」という要望は必ず発生します。リレーショナルデータベースであればマイグレーションスクリプトを用意しますが、ヘッドレスCMSにおいて何も考慮せずに稼働中のフィールドを削除したりデータ型を変更したりすると、既存のフロントエンドコード(APIレスポンスを前提に動いているコード)がクラッシュし、本番環境でシステム障害が発生します。
初期設計時に、フィールドの非推奨化(Deprecated)の流れや、バージョンごとのAPIエンドポイントの挙動について、利用するCMSの仕様を確認しておきましょう。
エンジニアがシステムの美しさだけを追求し、毎日コンテンツを入力する編集者の視点を無視するパターンです。例えばこんな現場が頻発します。
システムがどれほどモダンでも、コンテンツ更新が苦痛になればWebサイトの運用は滞ります。ヘルプテキスト・フィールドのグループ化・適切なバリデーションなど、編集者体験(Editor Experience)をモデリングと同時に設計することが、プロジェクト成功の隠れた条件です。
将来の英語展開やグローバル化の可能性があるのに、単一言語(日本語のみ)前提でフィールド設計してしまうパターンです。後から多言語対応する改修コストは非常に大きいため、初期段階で「言語ごとに切り替えるべきデータ」と「全言語で共通化すべきデータ」を明確に切り分けておくことが重要です。
なお、これらのアンチパターンを避けながらWordPressからヘッドレスCMSへ移行する具体的な手順については、以下の記事で7ステップに分けて解説しています。

2026-05-11T02:19:24Z
アンチパターンを回避し、エンジニアと運用者の双方にとって最適な環境を構築するための、実装レベルのベストプラクティスを3つ紹介します。
ヘッドレスCMSのスキーマ情報から、TypeScriptの型定義ファイル(types.ts)を自動生成する仕組みを導入しましょう。主要CMSの多くは、公式またはコミュニティ製のCLI・ライブラリを提供しています。
// 自動生成される型定義のイメージ例
export interface Author {
id: string;
name: string;
avatar: { url: string; alt: string; };
profile?: string;
}
export interface Article {
id: string;
title: string;
slug: string;
body: string;
publishedAt: string;
author: Author; // リレーションが解決された状態
categories: Category[]; // 多対多のリレーション
}スキーマ変更が自動的にTypeScript型に反映される仕組みがあれば、APIレスポンス構造の変更による不具合をビルド時点で検知できます。実行時エラーになる前に型エラーとして検出できるため、フロントエンドの安定性が飛躍的に向上します。
下書きをフロントエンド上で確認できる「プレビューモード」を、モデリング段階から設計に組み込みましょう。Next.jsのDraft Mode、NuxtのプレビューなどとヘッドレスCMSのDraft APIを連携させることで、編集者が「最終的にユーザーに見える形」で文章や画像を確認しながら執筆できます。これは編集者体験を一段引き上げる、極めて効果的な投資です。
※注: プレビュー画面を実際に表示するには、フロントエンド側(Next.js等)でプレビュー用のルーティングやデータフェッチの実装が別途必要です。「ヘッドレスCMS導入で自動的にプレビューが見られる」というわけではありません。エンジニアとディレクター間で認識を揃えておきましょう。
各フィールドには、必ず以下を設計時点で定義しておきます。
「あとから足せばいい」と思われがちですが、運用開始後に不正データが蓄積されてしまうと、後の一括クレンジング作業が膨大な工数になります。編集者が迷わず正しく入力できる環境を、初期から整えておきましょう。
ワイヤーフレームやデザインカンプ確定よりも前、要件定義の早い段階で着手することを推奨します。デザインが固まると「画面」起点の思考から抜け出しにくくなり、UI依存のモデルになりがちです。理想は「コンテンツインベントリ(情報の洗い出し)」→「コンテンツモデリング」→「ワイヤーフレーム」の順です。
WordPressのREST APIまたはWP-CLIで投稿・カスタムフィールド・メディアをエクスポートし、新CMSのImport API経由で投入するのが一般的です。ただしその前に必ずコンテンツモデリングをやり直すことが重要です。WordPressの構造をそのまま移植すると、ヘッドレスCMSの利点が活かせません。移行は「リファクタリングのチャンス」と捉えましょう。
「文章主体で、装飾は最小限」のコンテンツ(ブログ記事の本文など)であればリッチテキストで十分です。一方、「画像・CTA・特徴並列・FAQなど、構造の異なるパーツが組み合わさる」コンテンツ(LP・トップページ・特集ページ)であればブロック型を採用すべきです。多くの場合、両者を併用するハイブリッド設計が最適解になります。
本記事では、ヘッドレスCMSにおけるコンテンツモデリングについて、定義・従来型CMSとの違い・4ステップの設計手順・3つのケーススタディ・7つのアンチパターン・3つのベストプラクティスを解説しました。
コンテンツモデリングの本質を一言でまとめるなら、「データを画面から切り離し、意味として設計する」ということに尽きます。この発想を徹底することで、以下のすべてを同時に実現できます。
ヘッドレスCMSは「ツール」である以前に「設計思想」です。優れたコンテンツモデリングは、プロダクトの寿命を10年単位で延ばす力を持っています。これからヘッドレスCMSの導入を進める方も、すでに導入済みで課題を感じている方も、ぜひ本記事を設計の手引きとしてご活用ください。
次世代ヘッドレスCMS「NILTO」を活用し、
AIによる運用効率化とチームでのスムーズな
更新体験を最短で実現します。